libMEV - Data Methodologies
Published: dataSearchers, like artists, craft code with the strategic grace of a chessmaster, shaping sequences of logic in the digital realm, eternally etched in the blockchain.
Unfortunately deciphering these logic puzzles (bundles) in a generalizable way isn't a easy task. This is because we are essentially reverse engineering a complex puzzle, akin to identifying cake ingredients after being presented with a baked cake.
In this blogpost, we will be going through some of the data methodologies that we use in libMEV so everyone can be a MEV detective.

Prelude
libMEV is primarily designed to provide accurate MEV data, although it may not capture all the data, we are confident the data it does capture is accurate and reliable. Should you find any discrepancies, please alert us on our telegram.
Acknowlegements
We would like to thank the paradigm team. Cryo and reth is heavily used in our pipeline, and libMEV would not have been possible without those tools.
Data Collection
Before we can process the data, we first need to harvest the data. Using cryo, we extract the data in chunks of 1000 blocks. The type of data we're collecting are:
- block
- txs
- events
- balance_diffs
- storage_diffs
- eth_call (used for custom stuff, e.g. on-chain pricing)
We then store the data as-is into a blob storage, to be used for processing later on.
For the node, we are also using a vanilla version of reth. This is important later on as reth is one of the few EL nodes that has a specific feature we need in the post processing pipeline.
Data Processing
For the processing pipeline, we're using a custom implementation built from the ground up to work seamlessly with Apache Arrow (default output from cryo), and NOT JSON dumps from RPC calls.
This allows us to process the data much quicker, and at scale as we avoid the need of re-querying the raw data from the EL node.
Bundle? Not Bundle?
Just so everyone is on the same page: A bundle is a list of transactions that are in a particular order from the searcher.

Searchers want the bundles to be executed in the order they are sent, as they are only able to extract value if done so.
For a bundle to be identified in our system, it needs to be in one of the following bundle types, each with their own unique set of properties:
- Independent bundles
- Backrunning bundles
- Frontrunning and backrunning bundles
Independent Bundles
Independent bundles are simple, they're self-contained transactions and come mostly in the form of top-of-block arbitrages or liquidations, where there was leftover opportunity from the previous block, and do not rely on any prior transactions within the same block.
For liquidations, its very straightforward, as long as a liquidation event is emitted from a known borrowing protocol address (e.g. Aave, Compound), we can label it as so.
The challenge lies in distinguishing between an arbitrage and a regular token swap. Can you tell which is which below?
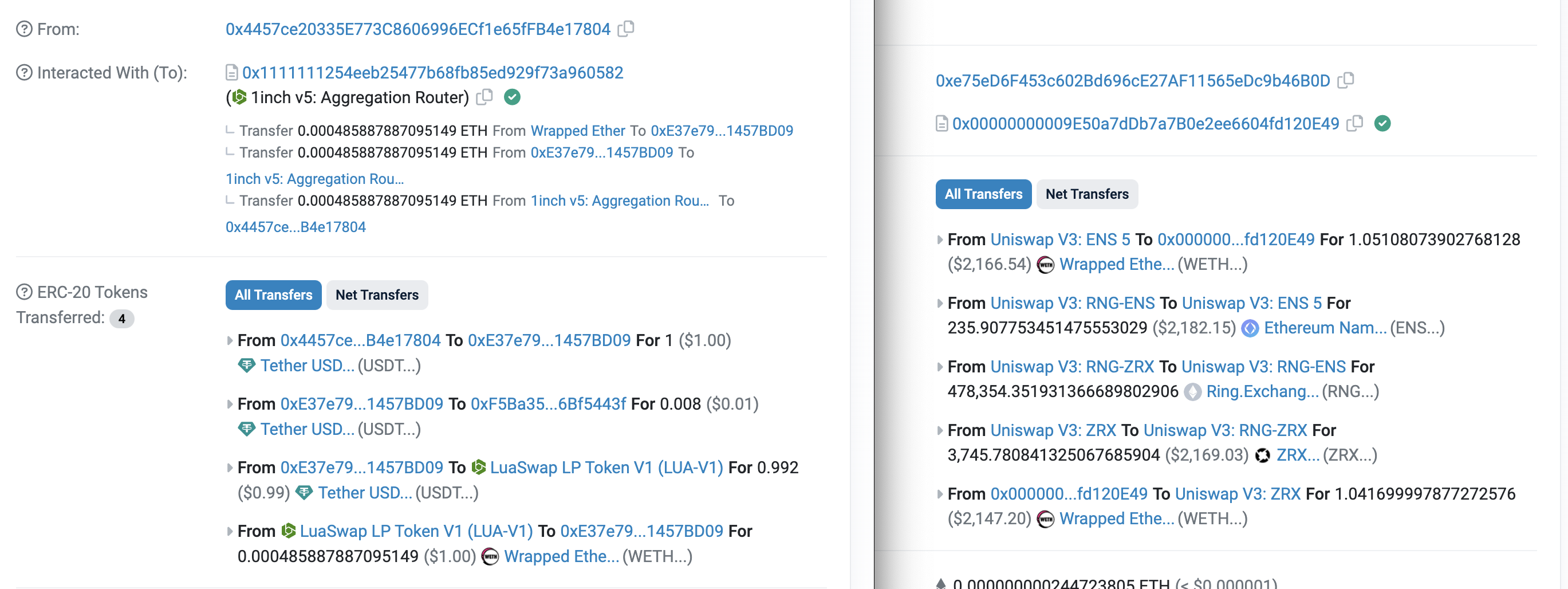
The transaction on the right stands out as an arbitrage. It doesn't ultilize the OneInch aggregator, whereas the left one does. Setting aside these explicit labels, how can we programatically determine if a transaction is an arbitrage or a regular token swap?
Lets revisit the definition of an arbitrage:

Note the key sentence: "...simulationeously buy and sell an asset..."
So, as long as the following properties hold true, we can confidently label it as an arbitrage:
- to_address is NOT a known DEX exchange address
- to_address / from_address sends and receives the same token
We can encapsulate the logic in the following pseudocode:
def is_token_cyclic(tx):
"""
Is the token transfer in this transaction cyclic?
If so its probably an arbitrage
"""
# For every token transfer
for tkn_xfer in tx.events.token_transfers:
# Find the token being transferred
token = tkn_xfer.address
# The sender of said token
sender = tkn_xfer.sender
# Only care about the MEV bot's contract address
if sender != tx.from_address or
sender != tx.to_address:
continue
# Check against all other token transfers
for other_tkn_xfer in tx.events.token_transfers:
# If its not the same token
# Ignore and continue
if other_tkn_xfer.address != token:
continue
# Token is cyclic!
# Sender buys and sells same asset
if other_tkn_xfer.recipient == sender:
return True
return False
def is_arbitrage(tx):
"""
Is the transaction an arbitrage?
"""
# If its sending to OneInch / Uniswap router its
# unlikely to be an arbitrage
if tx.to_address in KNOWN_DEX_ADDRESS:
return False
return is_token_cyclic(tx)Backrunning Bundles
Backrunning bundles are bundles where the searcher transaction is only inserted at the end of the bundle. This is because the opportunity only arises once the prior transactions have been executed.
# Backrunning
--start----------end-->
Tx0 -> Tx1 -> BackrunTxTo determine if the prior transactions hold any relevance to the final searcher transaction, we employ checks on the following properties:
- Slots
- Events
For the slots, if the preceeding transactions touches the same liquidity pair/pool slots, we have a high confidence that they are related. The logic roughly flows like so:
def is_txs_related_by_slots(tx1, tx2):
"""
Are the transactions related? (Slot)
"""
# Get relevant slots that were changed in the transaction
tx1_lp_slots = filter(lambda x: x.address is in LP_POOLS, tx1.slots)
tx2_lp_slots = filter(lambda x: x.address is in LP_POOLS, tx2.slots)
# Find the intersection of said slots
lp_slots_intersection = set(tx1_lp_slots).intersection(tx2_lp_slot)
# If there's an interaction of LP slots, its probably related
return len(lp_slots_intersection) > 0Whereas for the events, its a bit more tricky, as you're looking for opposite swap events between txs (that needs to be accounted on a protocol by protocol basis).
def is_txs_related_by_events(tx1, tx2):
"""
Are the transactions related? (Events)
"""
# Swap events
for swap_event in tx1.swap_events:
for reverse_swap_event in tx2.swap_events:
# Only care if its the same pool/pair
if swap_event.address !=
reverse_swap_event.address:
continue
# Tokens go opposite way
if swap_event.in_token == reverse_swap_event.out_token or
swap_event.out_token == reverse_swap_event.in_token:
return True
return FalseNow if we combine the two, we will have a high degree of confidence that our identified backrunning bundles will be correct.
def is_backrunning(txs):
"""
Given a list of txs, find out if they're related
"""
# Searcher transaction is the final tx
searcher_tx = txs[-1]
non_searcher_txs = txs[:-1]
# Keep iterating until a tx isn't relevant
for other_tx in non_searcher_txs.reverse():
# Exit loop if txs are not related
if not is_txs_related_by_slots(searcher_tx, other_tx) or
not is_txs_related_by_events(searcher_tx, other_tx):
return False
return TrueFrontrunning and Backrunning Bundles
This is the most complicated type of bundles because of all the possible permutations. The naive way to classify these types of bundles is by assuming that the transactions need to occur at the start and end of the bundle.
# Naive assumption
--start---------------end-->
Frontrun -> Tx0 -> BackrunTxThis is true for simple cases, but does not generalize well as advanced searchers will perform a backrun and a frontrun in the same transaction to extract the maximum value.
# Advanced searcher 1
--start---------------------------------------end-->
Tx0 -> BackrunTx0 + FrontrunTx1 -> Tx1 -> BackrunTx1You can also get more complicated bundles, i.e.
# Advanced searcher 2
--start----------------------------------------------------------------end-->
FrontrunTx -> Tx0 -> BackrunTx0 + FrontrunTx1 -> Tx1 -> Tx2 -> BackrunTx1+Tx2Note that the possible permutations these orderings can take is factorial, so its in our best interest if our algorithm generalizes.
Interestingly we can achieve this simply by reusing most of the logic previously defined. Composition over inheritance!
For a simple frontrun and backrun, we know they're related when:
- The frontrun tx and backrun tx closes a swap loop (i.e. is there an opposite swap event)
--start---------------end-->
Frontrun -> Tx0 -> BackrunTxHowever we also know that the frontrun might contain a backrun within it. So, we can also assume that:
- Any prior transactions before the first searcher tx that passes
is_backrunningis part of the bundle - The final searcher transaction needs to close a swap loop with one of the txs between the frontrun and backrun
--start---------------------------------------end-->
Tx0 -> BackrunTx0 + FrontrunTx1 -> Tx1 -> BackrunTx1
# Note that in a case like so, we would classify them as separate bundles
--start------------------------------------------------------------end-->
Tx0 -> BackrunTx0 + FrontrunTx1 -> Tx1 -> BackrunTx1 -> Tx2 -> BackrunTx2
# i.e.
[Tx0 -> BackrunTx0 + FrontrunTx1 -> Tx1 -> BackrunTx1] -> [Tx2 -> BackrunTx2]Lets try and encapsulate that into pseudocode:
def is_back_and_front_run(txs):
# Extract searcher transactions from the list of txs
searcher_txs = get_searcher_txs(txs)
# Final tx needs to be searcher tx
final_searcher_tx_idx = searcher_txs[-1]
if final_searcher_tx_idx != len(txs):
return False
# Make sure searcher txs contain a close loop
is_swap_closed = False
for searcher_tx1_idx in range(0, len(searcher_txs) - 1):
for searcher_tx2_idx in range(searcher_tx1_idx, len(searcher_txs)):
front_tx = searcher_txs[searcher_tx1_idx]
back_tx = searcher_txs[searcher_tx2_idx]
if is_txs_related_by_slots(front_tx, back_tx) and
is_txs_related_by_events(front_tx, back_tx):
is_swap_closed = True
if is_swap_closed:
break
if is_swap_closed:
break
# Loop doesn't even close
if not is_swap_closed:
return False
# If the first tx isnt the searcher tx, make sure
# its able to backrun
first_searcher_tx_idx = txs.indexOf(searcher_txs[0])
if first_searcher_tx_idx != 0:
tx0 = txs[first_searcher_tx_idx]
for i in range(0, first_searcher_tx_idx):
tx1 = txs[i]
# Its not a backrun, ser
if not is_txs_related_by_slots(tx0, tx1) or
not is_txs_related_by_events(tx0, tx1):
return False
# Make sure searcher txs closes a loop with a tx within
final_searcher_tx = searcher_txs[-1]
for i in range(first_searcher_tx_idx, final_searcher_tx_idx):
tx_between = txs[i]
# Its not a backrun, ser
if not is_txs_related_by_slots(final_searcher_tx, tx_between) or
not is_txs_related_by_events(final_searcher_tx, tx_between):
return False
# Pass all the checks!
return TrueBundle Processing
Now that we have a way to identify the bundles, the next step is to process the bundle. Information that is of interest:
- ETH tipped
- ETH burned
- Profit (in ETH and USDC)
Calculating ETH tipped/burned is simple: we look at the raw balance delta (obtained from balance_diffs) of the coinbase address (builder or validaor of the block).
The hard part is calculating the bundle profits given the various inventory changes:
- What is the token balance delta before and after the bundle?
- What is ETH/[TOKENS in bundle] exchange rate for the block?
Token Balance Delta
To calculate the token balance delta of the bundle, we rely on Transfer events (and on rare cases, Deposit/Withdraw events from WETH/sDAI).
Exchange Rate
Calculating the ETH/[TOKENS in bundle] exchange rate is a bit challenging for us due to how we architectured the data processing pipeline.
Remember, we are only relying on the extracted data from cryo. This means no querying the blockchain when processing historical chunks (this allows us to processing things much faster).
Instead we rely on on-chain swap events to determine the exchange rate of the token relative to ETH, which is painstakingly done on a protocol-by-protocol basis. e.g.
# Univ2 Sync
event Sync(uint112 reserve0, uint112 reserve1);
# Univ3 swap
event Swap(
address sender,
address recipient,
int256 amount0,
int256 amount1,
uint160 sqrtPriceX96,
uint128 liquidity,
int24 tick
)
# Bancor
event TokensTraded(
bytes32 contextId,
Token indexed pool,
Token indexed sourceToken,
Token indexed targetToken,
uint256 sourceAmount,
uint256 targetAmount,
uint256 bntAmount,
uint256 targetFeeAmount,
uint256 bntFeeAmount,
address trader
);
# ... and moreYou might ask, what happens if the tokens traded isn't against ETH? Good question. We have also extracted the price of popular base tokens (e.g. WBTC, USDC, USDT, DAI, rETH, stETH...) against ETH so we can perform conversions on the fly on a block-by-block basis. This has done well for the majority of cases.
With the inclusion the exchange rate of popular base tokens we are able to calculate the exchange rate of arbitrary tokens against ETH most of the time!
Bundle Post-Processing
Unfortunately, events are not the source of truth. Its the actual blockchain state that tells the truth. As such, we also have a post-processing pipeline:
-
We query the balance balance delta of tokens via
eth_callManyon reth before and after the transaction index in the block -
We calculate the exchange rate of said tokens by checking them on popular exchanges (e.g. Uniswap / Sushiswap/ Balancer / Pancakeswap / Curve...)
- The exchange rate will also be calculated against block number - 1
- If the exchange rate has changed significantly (i.e. x100 in one block), we will assume the token is worthless
- Rare cases where the price of a valid asset x10 in a block (i.e. CRV on block 17,807,830 -> 17,807,831)
- If the liquidity is less than some threshold, we will also assume the token is worthless
- If the token passes the above rule, we will take the median exchange rate from all popular exchanges
- The exchange rate will also be calculated against block number - 1
Once the historical chunks have been processed, the post-processing pipeline will be executed against the top and bottom N-number of transactions (sorted by profits) to ensure the outliers are removed.
Anormalies - $PAW
If we were to follow this transaction
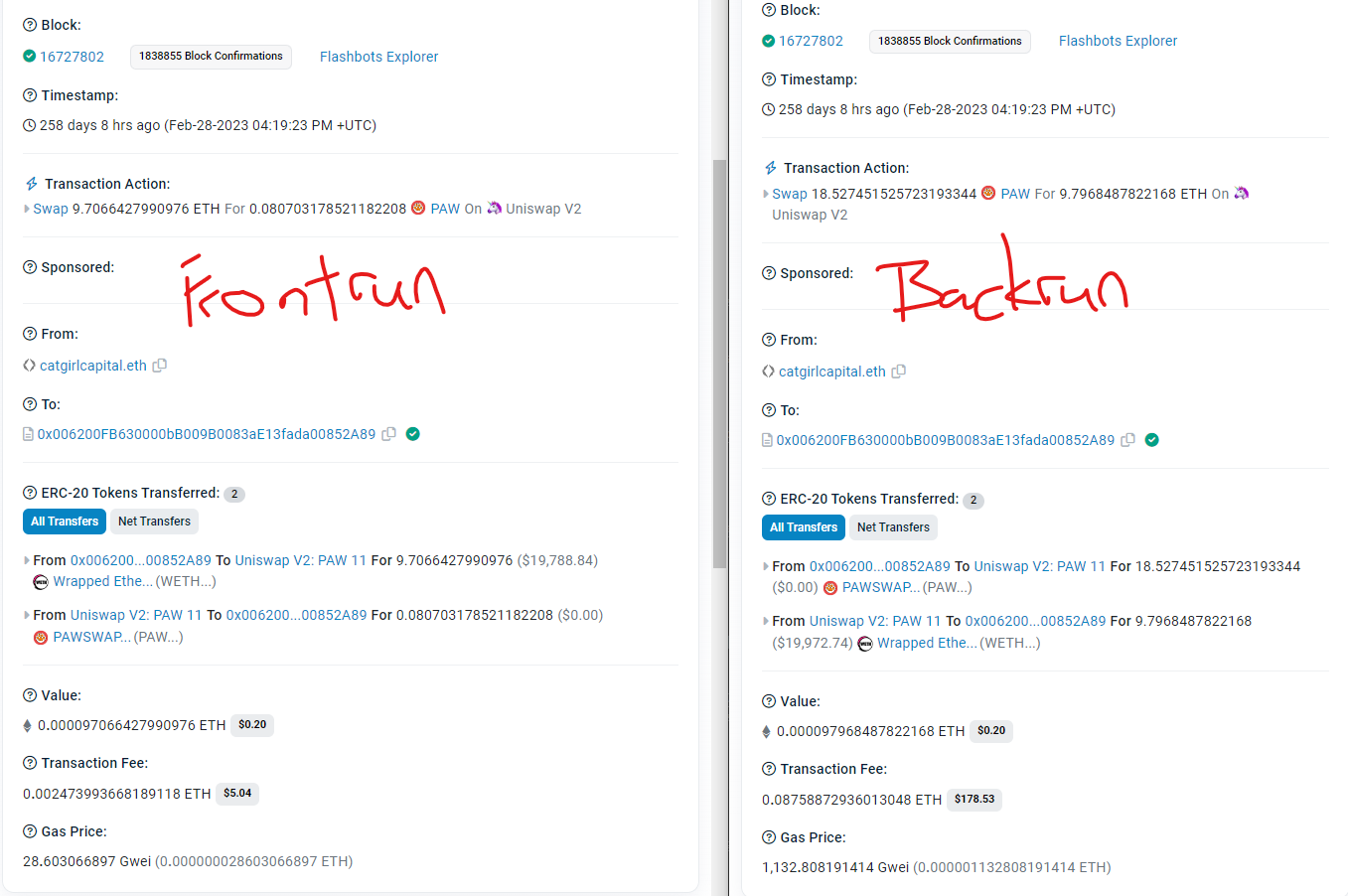
The exchange rate for $PAW would have been astronomical at the beginning (~100ETH = 1PAW).
In this bundle, searcher gained ~0.09 $ETH, but lost ~18.5 $PAW.
Without the post-processing pipeline, it would have been calculated that the searcher lost an equilavent of ~1800 ETH in this bundle, which is simply not true.
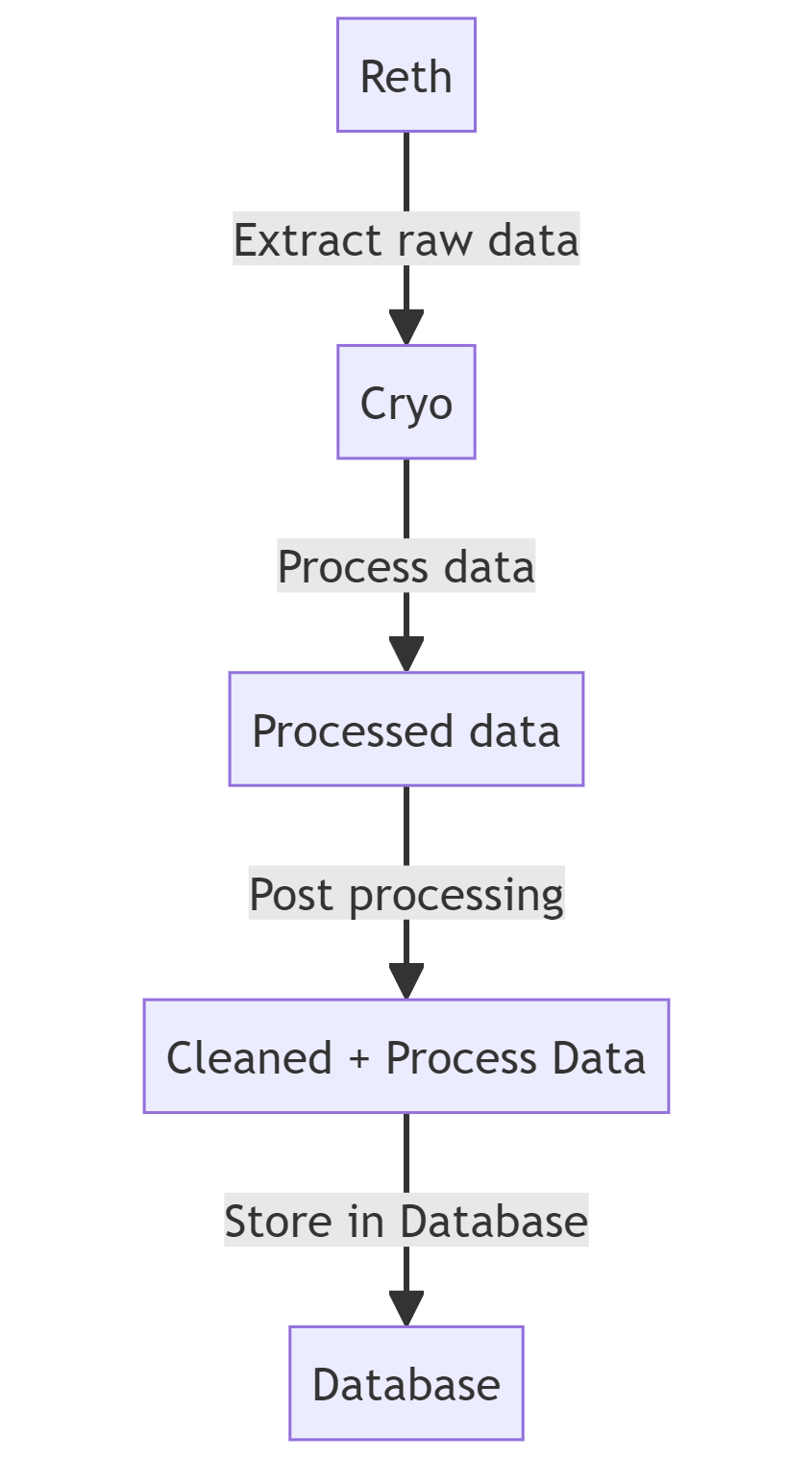
TLDR
FAQ
Why isn't [insert MEV address] here?
- We only index whitelisted searchers, for now. If you'd like us to index it, post it in the telegram group
How are the exchange rate of tokens determined?
- They're determined at the start of the bundle. For rare cases where there is low liquidity and the exchange rate is easily manipulated, we consider those tokens to be worthless. During post-processing, it'll be the median exchange rate against popular DEXes.